① 复合索引需要注意的点
复合索引,不要跨列或无序使用(最佳左前缀)
复合索引,尽量使用全索引匹配,也就是说,你建立几个索引,就使用几个索引
② 不要在索引上进行任何操作(计算、函数、类型转换),否则索引失效
explainselect*frombookwhereauthorid=1andtypeid=2; explainselect*frombookwhereauthorid*2=1andtypeid=2;
结果如下:
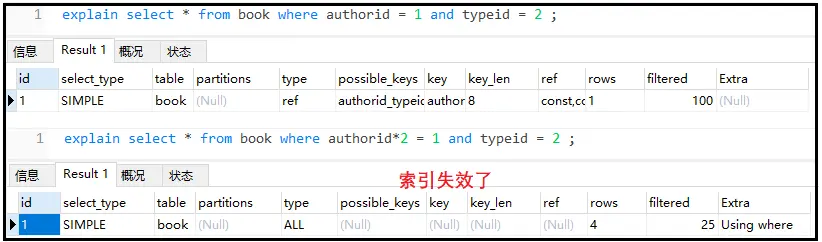
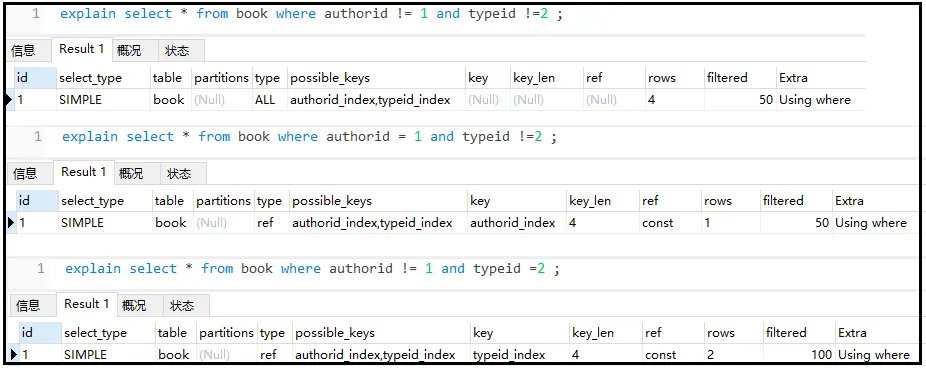
③ 索引不能使用不等于(!= <>)或is null (is not null),否则自身以及右侧所有全部失效(针对大多数情况)。复合索引中如果有>,则自身和右侧索引全部失效。
#针对不是复合索引的情况 explainselect*frombookwhereauthorid!=1andtypeid=2; explainselect*frombookwhereauthorid!=1andtypeid!=2;
结果如下:
再观看下面这个案例:
#删除单独的索引 dropindexauthorid_indexonbook; dropindextypeid_indexonbook; #创建一个复合索引 altertablebookaddindexidx_book_at(authorid,typeid); #查看执行计划 explainselect*frombookwhereauthorid>1andtypeid=2; explainselect*frombookwhereauthorid=1andtypeid>2;
结果如下:
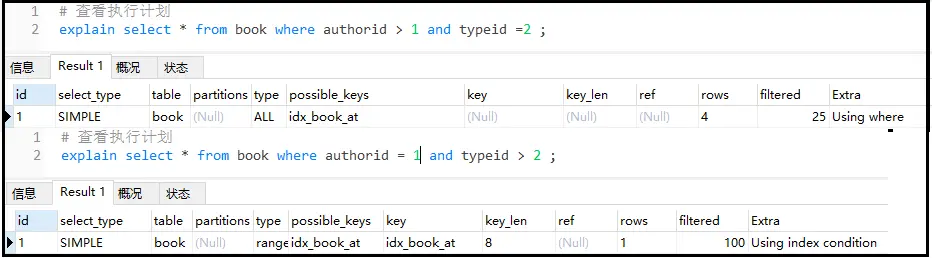
结论:复合索引中如果有【>】,则自身和右侧索引全部失效。
在看看复合索引中有【<】的情况:
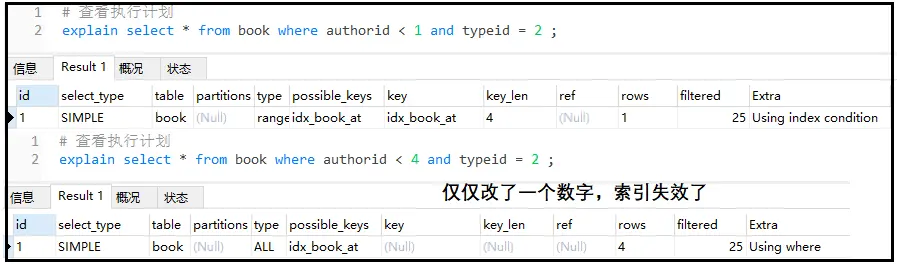
我们学习索引优化 ,是一个大部分情况适用的结论,但由于SQL优化器等原因 该结论不是100%正确。一般而言, 范围查询(> < in),之后的索引失效。
④ SQL优化,是一种概率层面的优化。至于是否实际使用了我们的优化,需要通过explain进行推测。
#删除复合索引 dropindexauthorid_typeid_bidonbook; #为authorid和typeid,分别创建索引 createindexauthorid_indexonbook(authorid); createindextypeid_indexonbook(typeid); #查看执行计划 explainselect*frombookwhereauthorid=1andtypeid=2;
结果如下:

结果分析:我们创建了两个索引,但是实际上只使用了一个索引。因为对于两个单独的索引,程序觉得只用一个索引就够了,不需要使用两个。
当我们创建一个复合索引,再次执行上面的SQL:
#查看执行计划 explainselect*frombookwhereauthorid=1andtypeid=2;
结果如下:

⑤ 索引覆盖,百分之百没问题
⑥ like尽量以“常量”开头,不要以’%'开头,否则索引失效
explainselect*fromteacherwheretnamelike"%x%"; explainselect*fromteacherwheretnamelike'x%'; explainselecttnamefromteacherwheretnamelike'%x%';
结果如下:
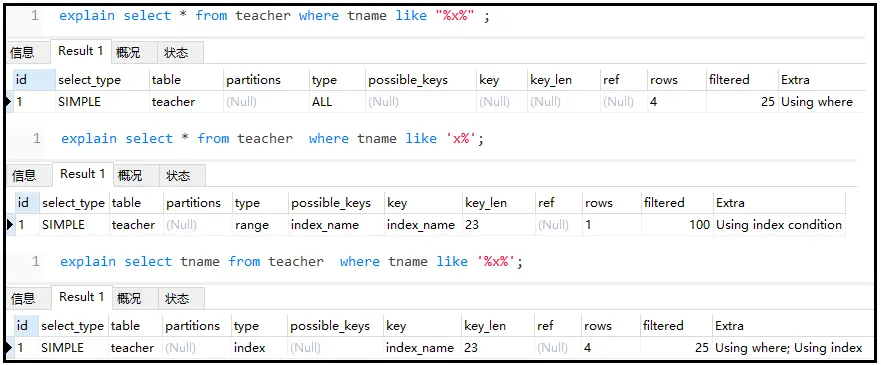
结论如下:like尽量不要使用类似"%x%"情况,但是可以使用"x%"情况。如果非使用 "%x%"情况,需要使用索引覆盖。
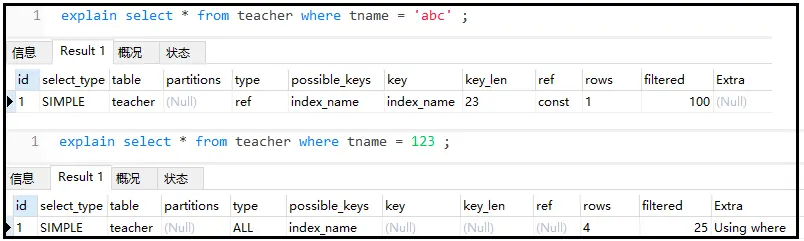
⑦ 尽量不要使用类型转换(显示、隐式),否则索引失效
explainselect*fromteacherwheretname='abc'; explainselect*fromteacherwheretname=123;
结果如下:
⑧ 尽量不要使用or,否则索引失效
explainselect*fromteacherwheretname=''andtcid>1; explainselect*fromteacherwheretname=''ortcid>1;
结果如下:
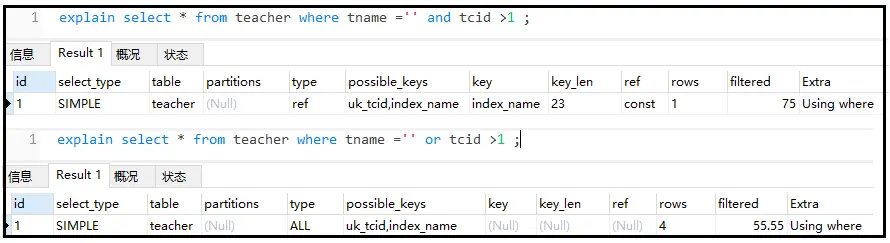
注意:or很猛,会让自身索引和左右两侧的索引都失效。
8、一些其他的优化方法
1)exists和in的优化
如果主查询的数据集大,则使用i关键字,效率高。
如果子查询的数据集大,则使用exist关键字,效率高。
select..fromtablewhereexist(子查询); select..fromtablewhere字段in(子查询);
2)order by优化
IO就是访问硬盘文件的次数
using filesort 有两种算法:双路排序、单路排序(根据IO的次数)
MySQL4.1之前默认使用双路排序;双路:扫描2次磁盘(1:从磁盘读取排序字段,对排序字段进行排序(在buffer中进行的排序)2:扫描其他字段)
MySQL4.1之后默认使用单路排序:只读取一次(全部字段),在buffer中进行排序。但种单路排序会有一定的隐患(不一定真的是“单路/1次IO”,有可能多次IO)。原因:如果数据量特别大,则无法将所有字段的数据一次性读取完毕,因此会进行“分片读取、多次读取”。
注意:单路排序 比双路排序 会占用更多的buffer。
单路排序在使用时,如果数据大,可以考虑调大buffer的容量大小:
#不一定真的是“单路/1次IO”,有可能多次IO setmax_length_for_sort_data=1024
如果max_length_for_sort_data值太低,则mysql会自动从 单路->双路(太低:需要排序的列的总大小超过了max_length_for_sort_data定义的字节数)
① 提高order by查询的策略:
选择使用单路、双路 ;调整buffer的容量大小
避免使用select * …(select后面写所有字段,也比写*效率高)
复合索引,不要跨列使用 ,避免using filesort保证全部的排序字段,排序的一致性(都是升序或降序)

本站推荐
-
1308
-
1182
-
1171
-
1124
-
1084