简介: 相较于大家熟练使用的 MVC 分层架构,领域驱动设计更适用于复杂业务系统和需要持续迭代的软件系统的架构模型。关于领域驱动设计的概念及优势,可以参考的文献非常多,大多数的同学都看过相关的书籍,所以本文不讨论领域驱动概念层面的东西,而是试图从编程实践的层面,对领域驱动开发做一些简单的介绍。

作者 | 昌夜
来源 | 阿里技术公众号
一 前言
相较于大家熟练使用的 MVC 分层架构,领域驱动设计更适用于复杂业务系统和需要持续迭代的软件系统的架构模型。关于领域驱动设计的概念及优势,可以参考的文献非常多,大多数的同学都看过相关的书籍,所以本文不讨论领域驱动概念层面的东西,而是试图从编程实践的层面,对领域驱动开发做一些简单的介绍。
加入阿里健康之后,我所在的团队也在积极推进领域驱动设计的应用,相关同学也曾给出优秀的脚手架代码,但目前看起来落地情况并不太理想,个人浅见,造成这种结果主要有四个原因。
- 大家更熟悉 MVC 的编程模式,需要快速实现某个功能的时候,往往倾向于使用较为稳妥、熟悉的方式。
- 大家对领域驱动编程应该怎么编写并没有一个统一的认知(Axon Framework[1] 对领域驱动设计实现的非常好,但它太“重”了)。
- DDD 落地本身就比较难,往往需要事件驱动和 Event Store 来完美实现,而这二者是我们不常用的。
- 领域驱动设计是面向复杂系统的,业务发展初期看上去都比较简单,一上来就搞领域驱动设计有过度设计之嫌。这也是领域驱动设计常常在系统不得不重构的是时候才被拿出来讨论的原因。
笔者曾在研发过程中研究、实践过领域驱动编程,对领域驱动框架 Axon Framework 也做了深入的了解,(也许是因为业务场景相对简单)当时落地效果还不错。抛却架构师的视角,从一线研发同学的角度来看,基于领域驱动编程的核心优势在于:
- 实施面向对象的编程模式,进而实现高内聚、低耦合。
- 在复杂业务系统的迭代过程中,保证代码结构不会无限制地变得混乱,因此保证系统可持续维护。
领域驱动开发最重要的当然是正确地进行领域拆解,这个拆解工作可以在理论的指导下,结合设计者对业务的深入分析和充分理解进行。本文假定开发前已经进行了领域划分,侧重于研究编码阶段具体如何实践才能体现领域驱动的优势。
二 保险领域知识简介
以保险业务为例来进行编程实践,一个高度抽象的保险领域划分如图所示。通过用例分析,我们把整个业务划分成产品域、承保、核保、理赔等多个领域(Bounded-Context),每个领域又可以根据业务发展情况拆分子域。当然,完备保险业务要比图中展现的复杂太多,这里我们不作为业务知识介绍的篇章,只是为了方便后续的代码实践。

三 领域驱动开发的代码结构
1 领域驱动的代码分层
可以使用不同的 Java 项目发布不同的微服务对领域进行隔离,也可以在同一个 Java 项目中,使用不同 module 进行领域隔离。这里我们使用 module 进行领域隔离的实现。但是无论采用何种方式进行领域隔离,领域之间的交互只能使用对方的二方包或者 API 层提供的 HTTP 服务,而不能直接引入其他领域的其他服务。
在每个领域内部,相对于 MVC 对应用三层架构的拆分,领域驱动的设计将应用模块内部分为如图示的四层。
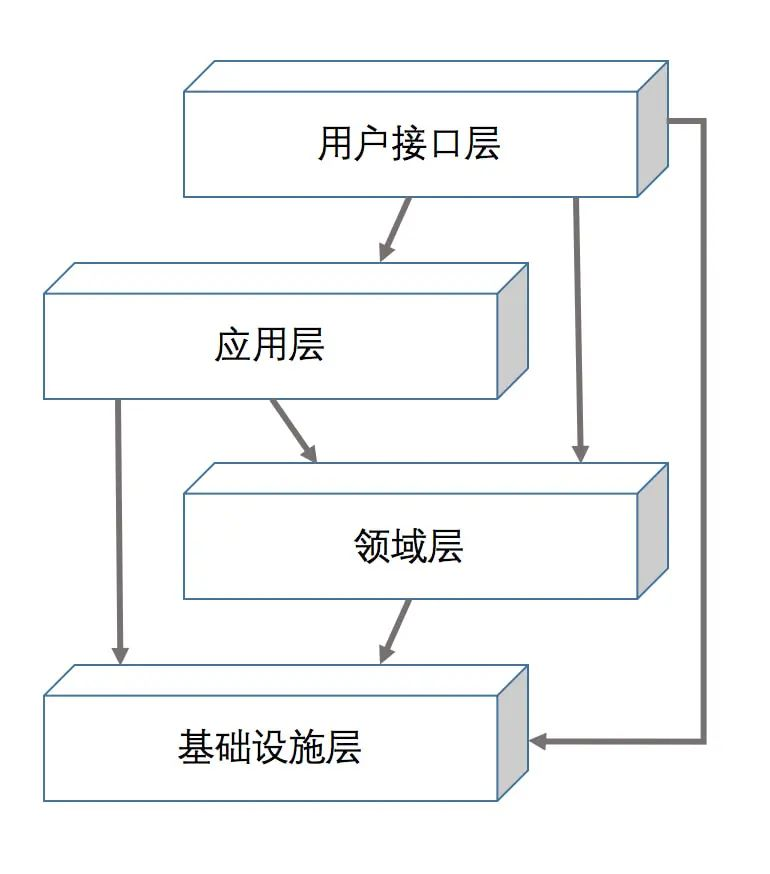
用户接口层
负责直接面向外部用户或者系统,接收外部输入,并返回结果,例如二方包的实现类、Spring MVC 中的 Controller、特定的数据视图转换器等通常位于该层。在代码层面常常使用的包命名可以是 interface, api, facade 等。用户接口层的入参、出参类定义采用 POJO 风格。
用户接口层是轻的一层,不含业务逻辑。安全认证,简单的入参校验(例如使用 @Valid 注解),访问日志记录,统一的异常处理逻辑,统一返回值封装应当在这层完成。
用户接口层所需要的功能实现是由应用层完成,这里一般不需要进行依赖倒置。编码时,该层可以直接引入应用层中定义的接口,因而该层依赖应用层。需要注意的是,虽然理论上用户接口层可以直接使用领域层和基础设施层的能力,但这里建议大家在对这种用法熟练掌握前,最好采用严格的分层架构,即当前层只依赖其下方相邻的一层。
应用层
应用层具体实现接口层中需要功能,但该层并不实现真正的业务规则,而是根据实际的 use case 来协调调用领域层提供的能力。
消息发送、事件监听、事务控制等建议在这一层实现。在代码层面常常使用的包命名可以是 application, service, manager 等。它用来取代 Spring MVC 中 service 层,并把业务逻辑转移到领域层。
领域层
领域层面向对象的,它主要用来体现和实现领域里的对象所具备的固有能力。因此,在领域驱动编程中,领域层的编程实现是不允许依赖其他外部对象的,领域层的编程是在我们对领域内的对象所具备的固有能力和它要在当前业务场景下展现什么样的能力有一定了解后,可以直接编码实现的。
例如我们最开始接触面向对象的编程的时候,常常会遇到的一个例子是鸟会飞、狗会游泳,假设我们的业务域只关心这些对象的运动,我们可以做如下的实现。
public interface Moveable {
void move();
}
public abstract class Animal implements Moveable {}
public class Bird extends Animal {
public void move(){
//try to fly
System.out.println("I'am flying");
}
}
public class Dog extends Animal {
public void move(){
//try to swim
System.out.println("I'am swimming");
}
}基于领域驱动的编程需要这样(充血模型)去实现对象的能力,而不是像我们在 MVC 架构中常常使用贫血模型,把业务逻辑写在 service 中。
当然,即使采用了这样的编程方式,距离实现领域驱动还差的远,一些看似简单的问题就可能给我们带来巨大的不安感。例如复杂的对象应当如何初始化和持久化?同样一个事物在不同领域都存在,但其关注点不同时这个事物应当分别怎么抽象?不同领域的对象需要对方的信息时,应当怎么获取?
这些问题,我们也会在代码示例部分尝试给出一些参考的方案。
基础设施层
基础设施层为上面各层提供通用的技术能力,例如监听、发送消息的能力,数据库/缓存/NoSQL数据库/文件系统等仓储的 CRUD 能力等。
2 小结
根据对领域驱动设计各层的进一步分析,一个更加具体化的分层结构如下。
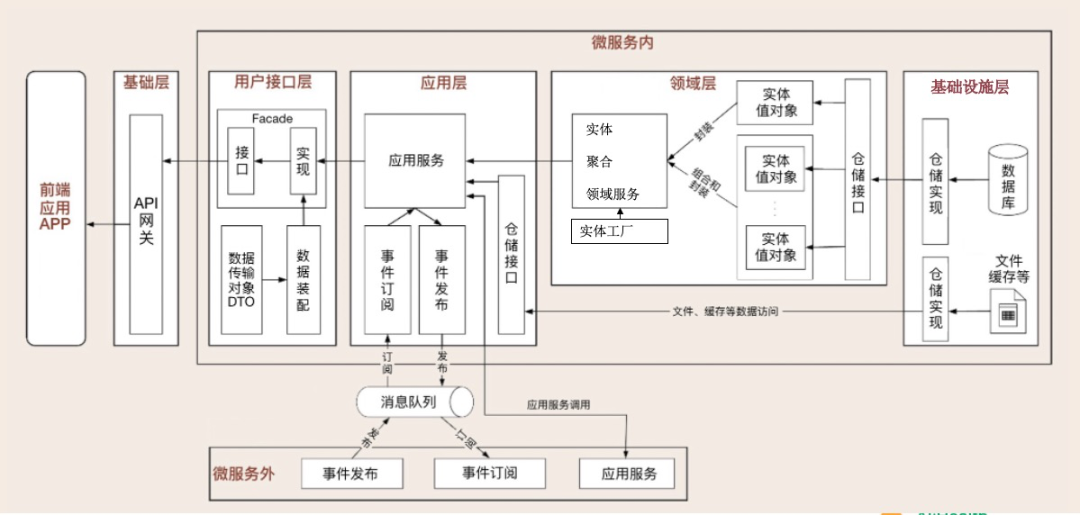
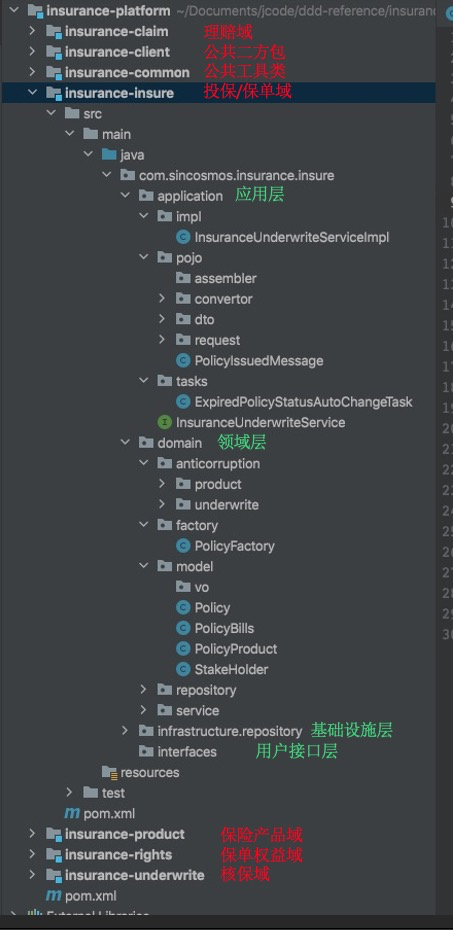
基于上面的分层原则,前述保险领域一个可以参考的代码结构如下,我们将在下面编码示例详细讲解每一个分包的理念和作用。
四 领域驱动开发的代码
理论上,DOMAIN 不依赖其他层次且是业务核心,我们应当先编写领域层代码,但是一则由于我们对保险领域知识的欠缺,可能不清楚保单到底有哪些固有能力;二则为了便于讲解,因此我们直接借助一个用例来展示代码。
1 用例
- 用户在前端页面选择保险产品,选择可选的保障责任,输入投/被保人信息,选择支付方式(分期/趸交等)并支付后提交投保请求;
- 服务端接受投保请求 -> 核保 -> 出单 -> 下发保单权益。
这里用例 1 是用例 2 的前置用例,我们假定用例 1 已经顺利完成(用例 1 中完成了费率计算),只来实现用例 2,并且用例 2 也只是大略的实现,只要能把代码样式展示即可。
2 用户接口层编程实践
分包结构
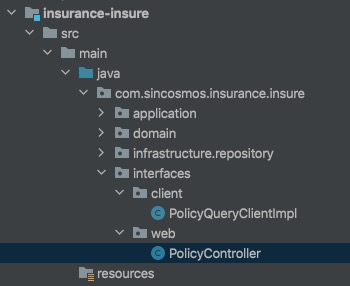
其中 client 是对 inusurance-client (公共二方包) 部分的实现,web 是 rest 风格接口的实现。
用例代码
@AllArgsConstructor
@RestController
@RequestMapping("/insure")
public class PolicyController {
private final InsuranceInsureService insuranceInsureService;
/**
* 投保出单
* @param request
* @return 保单 ID
*/
@RequestMapping(value = "/issue-policy", method = RequestMethod.POST)
public String issuePolicy(IssuePolicyRequest request){
return insuranceInsureService.issuePolicy(request);
}
}这里用到的入参和返回值的类都在应用层中定义。
3 应用层编程实践
1、分包结构
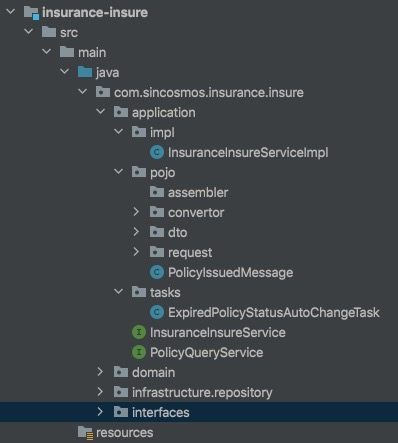
- 其中最外层接口是面向具体业务场景的,可以根据业务发展再进行分包。
- pojo 包中定义了应用层用到的各种数据类(上面的 IssuePolicyRequest 就在这里)及其向其他层传播时需要进行类型转换的转化器。
- tasks 包中定义了一些定时任务的入口。
注意,在领域编程实践中,会需要非常多的类型转换,我们可以借助一些框架(例如 MapStruct[2])来减少这些类型转换给我们带来的繁琐工作。
2、用例代码
@Service
@AllArgsConstructor
public class InsuranceInsureServiceImpl implements InsuranceInsureService {
private final PolicyFactory policyFactory;
private final StakeHolderConvertor stakeHolderConvertor;
private final PolicyService policyService;
/**
* 事务控制一般在应用层
* 但是需要注意底层存储对事务的支持特性
* 底层是分库分表时,可能需要其他手段来保证事务,或者将非核心的操作从事务中剥离(例如数据库 ID 生成)
*/
@Override
@Transactional(rollbackFor = Exception.class)
public String issuePolicy(IssuePolicyRequest request) {
Policy policy = policyFactory.createPolicy(request.getProductId(),
stakeHolderConvertor.convert(request.getStakeHolders()));
//出单流程控制
policyService.issue(policy);
PolicyIssuedMessage message = new PolicyIssuedMessage();
message.setPolicyId(policy.getId());
MQPublisher.publish(MQConstants.INSURANCE_TOPIC, MQConstants.POLICY_ISSUED_TAG, message);
return policy.getId().toString();
}
}这里代码展示的是应用层对用例 2 的处理。
- 使用领域层的工厂类构建 Policy 聚合。如果需要传递复杂对象,需要先用类型转换器将应用层的数据类转化为领域层的实体类或者值对象。
- 使用领域层服务控制出单流程
- 发送出单成功消息,其他领域监听到感兴趣的消息会进行响应。
4 领域层编程实践
1、分包结构
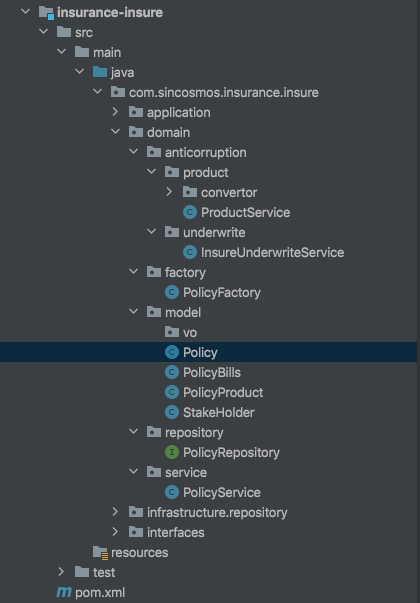
这里领域层一共有5个一级分包。
- anticorruption 是领域防腐层,是当前领域需要获知其他领域或者外部信息时,对其他领域二方包的封装。防腐层从代码层面来看,可以避免调用外部客户端时,在领域内部进行复杂的参数拼装和结果的转换。
- factory 解决了复杂聚合的初始化问题。我们设计好领域模型供外部调用,但如果外部也必须使用如何装配这个对象,则必须知道对象的内部结构。对调用方开发来说这是很不友好的。其次,复杂对象或者聚合当中的领域知识(业务规则)需要得到满足,如果让外部自己装配复杂对象或聚合的话,就会将领域知识泄露到调用方代码中去。需要注意的是,这里主要是把聚合或实体需要的数据填充进来,而不涉及对象的行为。
因此这里工厂的核心作用是从各处拉取初始化聚合或实体所需要的外部数据。
@Service
@AllArgsConstructor
public class PolicyFactory {
/**
* 产品领域防腐层服务
*/
private final ProductService productService;
/**
* 从各种数据来源查询直接能查到的前置数据,填充到 policy 中
* @param productId
* @param stakeHolders
* @return
*/
public Policy createPolicy(Long productId, List<StakeHolder> stakeHolders) {
PolicyProduct product = productService.getById(productId);
//其他填充数据,这里调用了聚合自身的静态工厂方法
Policy policy = Policy.create(product, stakeHolders);
return policy;
}
}- model 中是领域对象的定义。其中 vo 包中定义了领域内用到的值对象。可以看到这里有PolicyProduct 这样一个保险产品类,在投保领域,我们关注的是和保单相关的某个产品及其快照信息,因此我们在这里定义一个保单保险产品类,防腐层负责把从产品域获得的保险产品信息转换为我们关心的保单保险产品类对象。
按照领域驱动设计的最佳实践,领域对象模型中不允许出现 service、repository 这些用以获取外部信息的东西,它的核心概念是一个完备的实体初始化完成后,它能做什么,或者它经历了什么之后状态会发生怎样的变化。
下面是领域内核心的聚合 Policy 的示例代码。
@Getter
public class Policy {
private Long id;
private PolicyProduct product;
private List<StakeHolder> stakeHolders;
private Date issueTime;
/**
* 工厂方法
* @param product
* @param stakeHolders
* @return
*/
public static Policy create(PolicyProduct product, List<StakeHolder> stakeHolders){
Policy policy = new Policy();
policy.product = product;
policy.stakeHolders = stakeHolders;
return policy;
}
/**
* 保单出单
*/
public void issue(Long id) {
this.id = id;
this.issueTime = new Date();
}
}- repository 是仓储包,只定义仓储接口,不关心具体实现,具体的实现交由基础设施层负责,体现了依赖倒置的思想。
- service 是领域服务,它定义一些不属于领域对象的行为,但是又有必要的操作,比如一些流程控制。
2、用例代码
@Service
@AllArgsConstructor
public class PolicyService {
private final InsureUnderwriteService insureUnderwriteService;
private final PolicyRepository policyRepository;
public void issue(Policy policy) {
if(!insureUnderwriteService.underwrite(policy)){
throw new BizException("核保失败");
}
policy.issue(IdGenerator.generate());
//保存信息
//policyRepository.save(policy);
policyRepository.create(policy);
}
}这里注意我们注掉了一行 policyRepository.save(policy);,那么为什么要区别 save 和 create 呢?
save 是领域驱动设计中最正确的做法:我的聚合或者实体有变动,仓储不用关心是新建还是更新,帮我保存起来就好了。听上去很美好,但对关系型数据库存储却是很不友好的。因此,在我们的场景里,需要违背一下书上所谓的最佳实践,我们告诉仓储是要新建还是更新,甚至如果是更新的话更新的是哪些列。
另外领域驱动的最佳实践是基于事件驱动的,AxonFramework 对其有完美的实现,应用层发出一个 IssuePolicyCommand 指令,领域层接收该指令,完成保单创建后发出PolicyIssuedEvent,该 event 会被监听并且持久化到 event store 中。这种方式目前看起来在我们这里落地的可能性不大,不做更多介绍。
5 基础设施层编程实践
1、分包结构

这里只展示了 repository 的实现,但实际上这里还有 RPC 调用的二方包实现类注入等很多内容。上文说到领域层不关心仓储的实现,交由基础设施层负责。基础设施层可以根据需要使用关系型数据库、缓存或者NoSQL,领域层是无感知的。这里我们以关系型数据库为例来,dao 和 dataobject 等都可以使用例如 mybatis generator 等工具生成,领域对象 和 dataobject 之间的转换由 convertor 负责。
2、用例代码
@Repository
@AllArgsConstructor
public class PolicyRepositoryImpl implements PolicyRepository {
private final PolicyDAO policyDAO;
private final StakeHolderDAO stakeHolderDAO;
private final PolicyConvertor policyConvertor;
private final StakeHolderConvertor stakeHolderConvertor;
@Override
public String save(Policy policy) {
throw new UnsupportedOperationException();
}
@Override
public String create(Policy policy) {
policyDAO.insert(policyConvertor.convert(policy));
stakeHolderDAO.insertBatch(stakeHolderConvertor.convert(policy));
//...其它数据入库
return policy.getId().toString();
}
@Override
public void updatePolicyStatus(String newStatus) {
}
}这部分代码比较简单,无需赘言。
五 结语
关于领域驱动,笔者仍处于初学者阶段,再好的设计,随着业务的发展,代码也难免变得混乱,这个过程中,每个参与者都有责任。最后,总结一下我们维持代码初心的一些原则,和大家分享。
- 深入理解业务场景,分析用例,进行正确的领域划分。
- 确定好实现方式后,大家尽量按照既定模式/风格编程,有异议的地方可以一起讨论后统一改动。
- 不引入不必要的复杂度。
- 不断对系统设计进行优化改进,对繁琐的代码,用设计模式进行优化。
- 写注释。
[1]https://docs.axoniq.io/reference-guide/?spm=ata.21736010.0.0.468f6b14I9wBgS
[2]https://mapstruct.org/?spm=ata.21736010.0.0.468f6b14I9wBgS
