我们知道String.hashCode()返回的是一个int类型的数值,那当某个字符串的hash值超出int的最大范围后会发生什么呢?
首先我们来看下String.hashCode()的源码,看看它是如何计算一个字符串的hash值:
/** The value is used for character storage. */ private final char value[]; /** Cache the hash code for the string */ private int hash; // Default to 0 /** * Returns a hash code for this string. The hash code for a * {@code String} object is computed as * <blockquote><pre> * s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] * </pre></blockquote> * using {@code int} arithmetic, where {@code s[i]} is the * <i>i</i>th character of the string, {@code n} is the length of * the string, and {@code ^} indicates exponentiation. * (The hash value of the empty string is zero.) * * @return a hash code value for this object. */ public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
从源码中我们可以看出,
1.String有一个私有变量hash来缓存哈希值,即当该串第一次调用hashCode()方法时,hash默认值为0,继续执行,当字符串长度大于0时计算出一个哈希值赋给hash,之后再调用hashCode()方法时不会重新计算,直接返回hash
2.计算时,使用的是该字符串截成的一个字符数组,用每个字符的ASCII值进行计算,根据注释可以看出哈希计算公式是:s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1],n是字符数组的长度,s是字符数组
3.算法中还有一个乘数31,为什么使用31呢?
- hash函数必须选用质数(在大于一的自然数中除了1和它本身以外不再有其他因数的自然数)这是被科学家论证过的hash函数减少冲突的理论
- 如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为使用偶数相当于位移运算(低位补0)
- 使用31有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能:31*i == (i<<5)-i,现代的VM可以自动完成这种优化
- 31是个不大不小的质数,兼顾了性能和冲突率,我们利用s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]这个公式,如果乘数换做是2或101计算字符串"abcde"这六个字母的hash值时,乘数为2,2^(6-1) = 32,乘数为101, 101^(6-1) = 10,510,100,501 一个太小一个太大。太小hash冲突概率大,太大过于分散占用存储空间大,所以选择一个不大不小的质数很有必要
也有实验证明31这个数值更优:
整形的数值区间是 [-2147483648, 2147483647],区间大小为 2^32。
所以这里可以将区间等分成64个子区间,每个子区间大小为 2^26
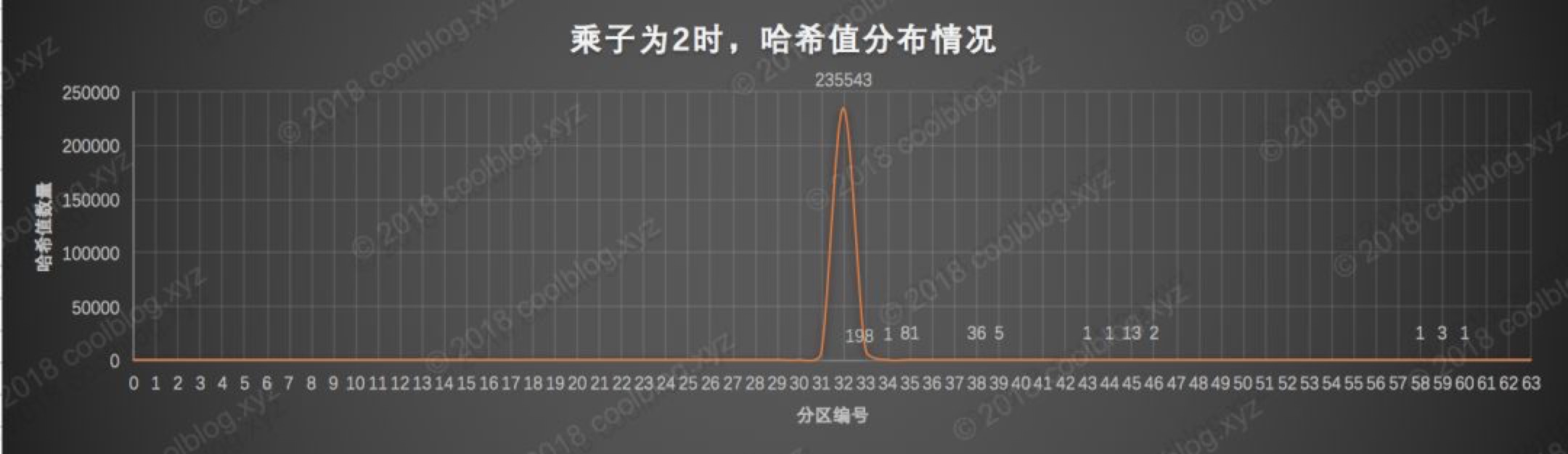
乘子2算出的哈希值几乎全部落在第32分区,也就是 [0, 67108864)数值区间内,落在其他区间内的哈希值数量几乎可以忽略不计。这也就不难解释为什么数字2作为乘子时,算出哈希值的冲突率如此之高的原因了
和2基本上差不多
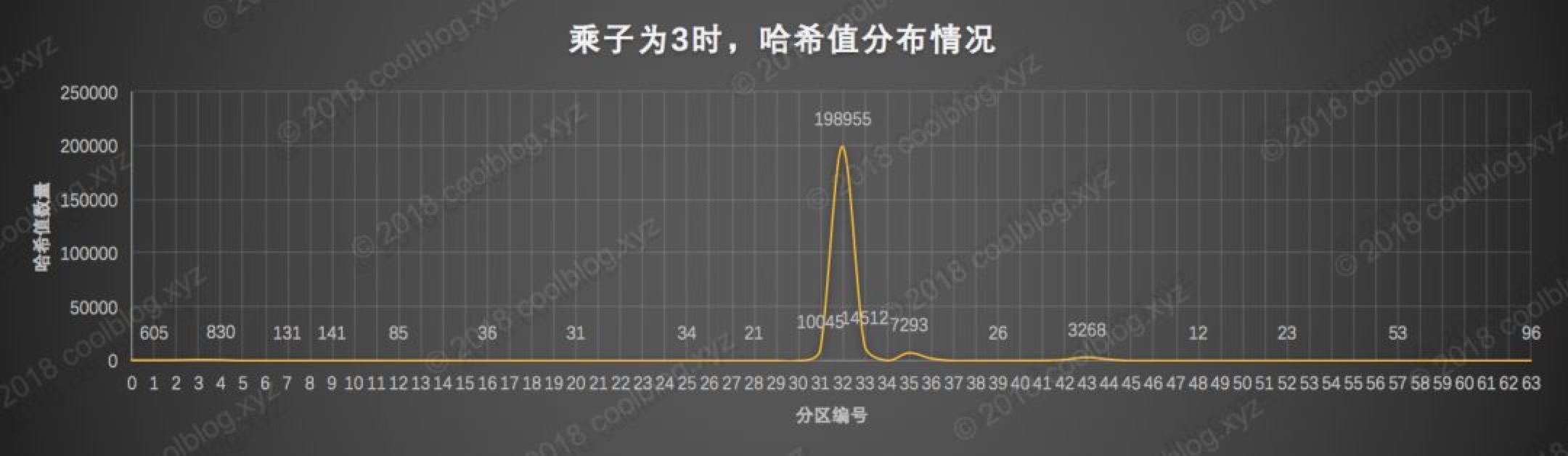
相对不错
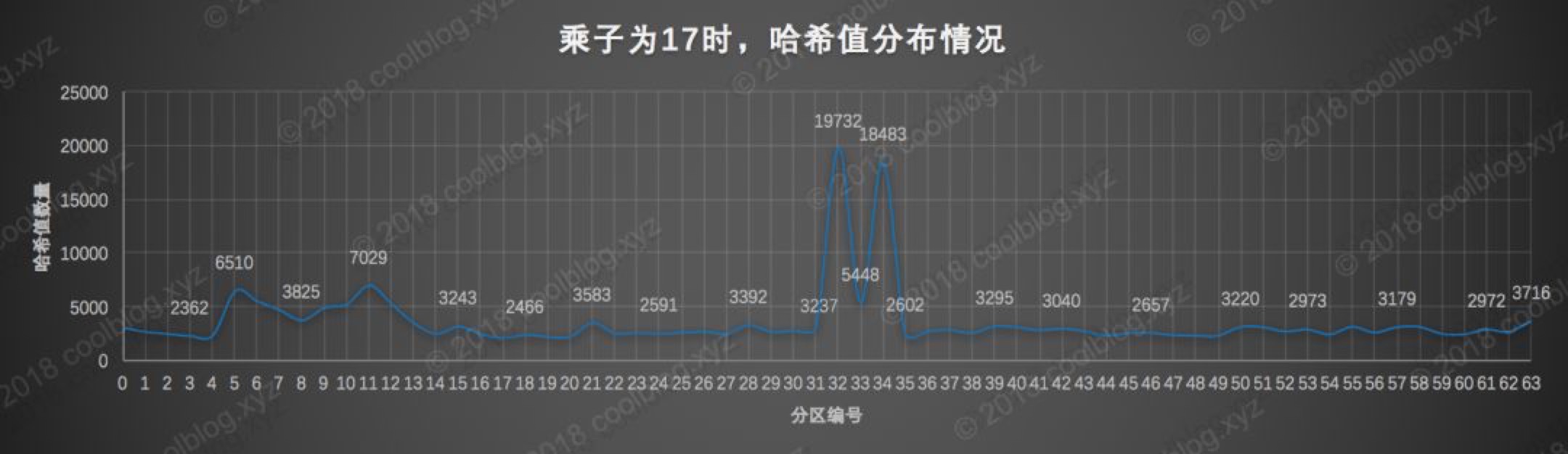
分散比较均匀了
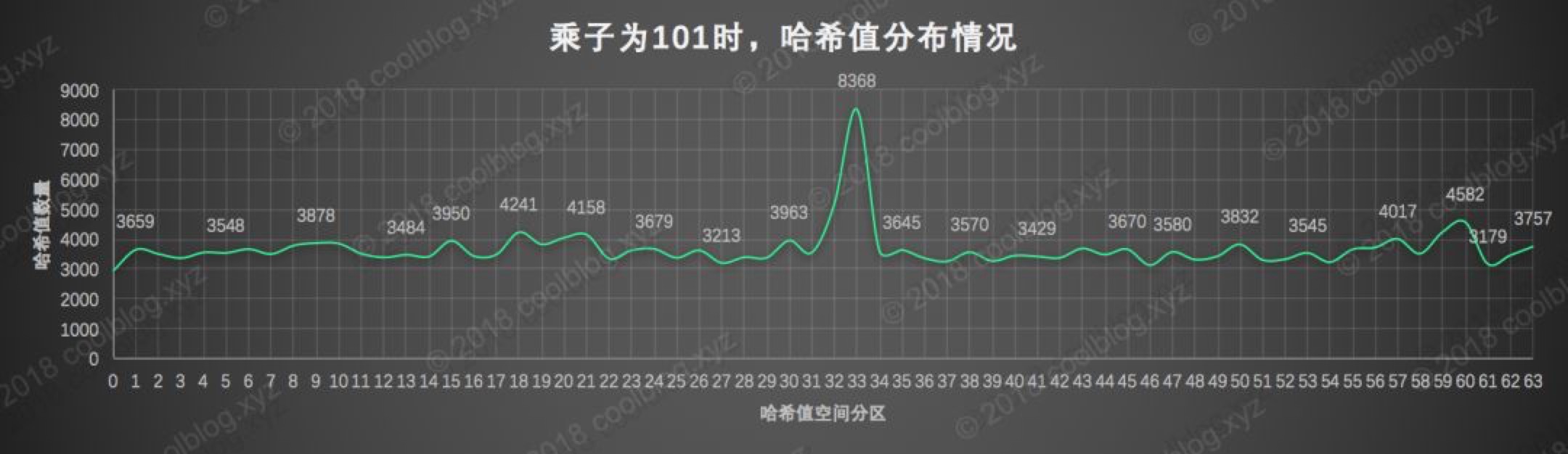
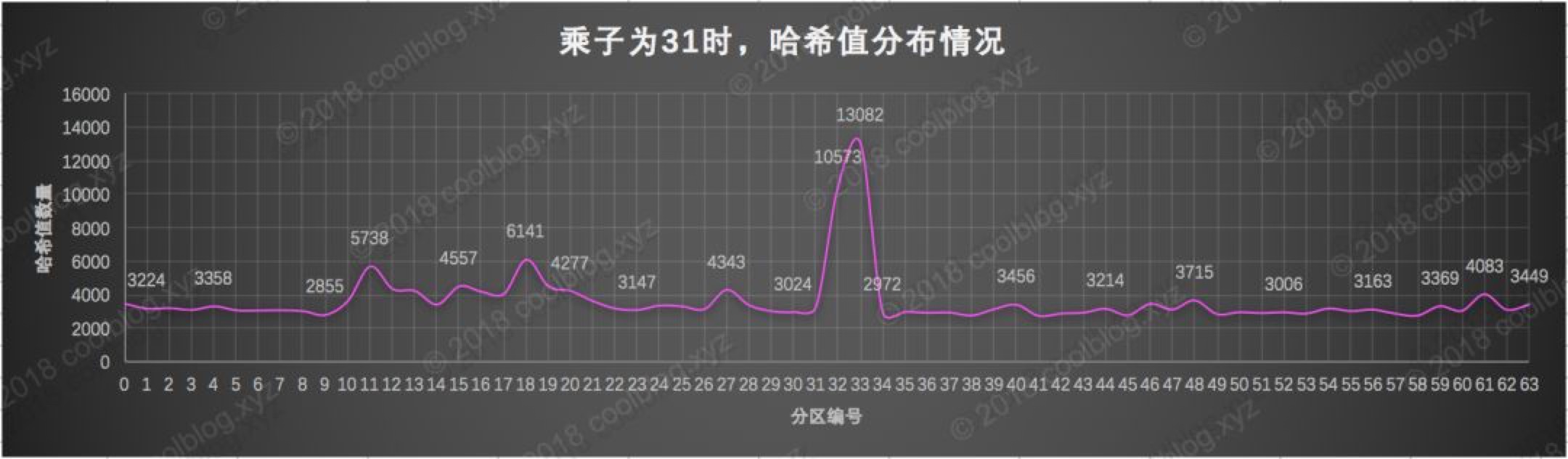
冲突率很低,这也说明哈希值溢出并不一定会导致冲突率上升。但是还是因为乘积太大导致整数溢出的问题。所以兼顾性能和冲突率31最为合适
看完了String.hashCode()的源码,可以肯定的说一定会有字符串计算出来的hash值是超出int的最大取值范围的,那这时候程序会怎么处理呢?
测试代码:
@Test public void test3() { System.out.println("a".hashCode()); System.out.println("ab".hashCode()); System.out.println("abc".hashCode()); System.out.println("abcd".hashCode()); System.out.println("abcde".hashCode()); System.out.println("abcdef".hashCode()); System.out.println("abcdefg".hashCode()); }
结果输出:
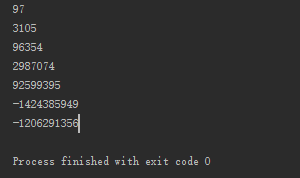
最后两个输出的是负数,按照公式来计算的话,"abcdef"的hash值应该是9259939531+102=2870581347,这明显已经超出了int的取值范围
在计算9259939531=2870581245时,结果已经超出了int的最大范围,这时Java虚拟机做了默认的类型提升,把中间结果用long类型存放,然后计算2870581245+102=2870581347返回结果依然不能被int容纳,根据Java的基础类型的变窄转换规则,取结果的低32位,然后在计算机中实际是用补码存储的,正数的补码=原码,所以2870581347在计算机中是这样的:
00000000 00000000 00000000 00000000 10101011 00011001 10011000 01100011
基于变窄转换,丢弃高于int宽度的部分,得到补码:
10101011 00011001 10011000 01100011
然后首位是符号位,1代表负数,负数的补码=反码+1,反推得到反码:
10101011 00011001 10011000 01100010
负数的反码=符号位不变,原码按位取反,反推得到原码:
11010100 11100110 01100111 10011101=-1010100 11100110 01100111 10011101
转化成十进制就是"-1424385949",所以就有了上图的输出结果
原文链接:https://blog.csdn.net/weixin_45661382/article/details/104824679
